
Using word vectors to decipher Swedish culture
Intro
Can culture be quantified? Taking for example a statement like:
"Society has become more liberal over the years."
or
"In Sweden it is particularly important not to brag."
How do we know whether these statements are accurate?
Such questions relating to culture often prove refractory to quantitative analysis. However, recent developments in natural language processing (NLP) are providing new avenues of investigation. For example, the development of high quality word embeddings provides a mechanism for quantifying the meaning of words, as derived from input text corpora.
Here, I present an attempt to use word vectors to analyse culture. In particular, I have analysed word2vec word embeddings trained on English and Swedish wikipedia corpuses, to examine whether there are particular areas of expression that are enriched or depleted in one language compared to another.
Below, I explain the analysis. To skip straight to the nice meaty results, click here.

Word2vec and machine translation
Word2vec is very cool indeed. The method produces high dimensional word embeddings by training a neural network to predict words given their context, from an input text corpus. The resulting word vectors have interesting semantic properties. To take a famous example, if we take the vector for the word "King", subtract the vector for "man" and add the vector for "woman", we end up with a vector located close to the word "Queen".
Mikolov et al. also found that the relative positioning of words in one language are preserved to some extent when taking their translations in a second language. The authors showed how this can facilitate machine translation of words: A transformation matrix can be trained, such that multiplication of a word vector in language lquery will result in a vector that is close (on average) to a suitable translation in language ltarget.
This leads to my project. One could apply Mikolov's method to all words in language lquery such that they are comparable to words in language ltarget. This would result in two word landscapes in high-dimensional space, which can themselves be compared for various properties. For example, one language may be enriched or depleted for specific areas of expression relative to another. I implemented this approach and used it to compare English and Swedish, with the aim of identifying interesting cultural differences.
Implementing Mikolov et al.
The code I wrote for this project is available on GitHub. I implemented the project as a series of small python scripts, which cobble together to form a rough analysis pipeline. I focused on completing the project, rather than on software engineering per se, so some of it is a bit rough and ready.
My work relies on the gensim library, which includes amongst other things an implementation of the word2vec training algorithm. I found the library extremely intuitive and powerful.
I produced word vectors and a transformation matrix through the following steps:
- Processing the wikipedia corpus for input to gensim, for both English and Swedish.
- Training word2vec models using gensim, including short phrases in the vocabulary in addition to individual words.
- Filtering the resulting word vectors to only retain words in predefined English and Swedish vocabularies
- Obtaining translations for the most frequent words using the Microsoft translation API, to use for training the transformation matrix, and retrieving corresponding word vector pairs.
- Training the transformation matrix, by implementing gradient descent with the loss function defined in Mikolov et al.:
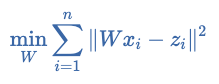
- Here, W is the translation matrix, xi is the i th training word vector in the query language and zi is the word vector for the corresponding translation. I used Theano to implement the gradient descent in this step, and manually checked the partial derivatives on a small example matrix to make sure I got the same results as Theano (having not used Theano prior to this). I plotted the cost function with increasing training iterations in order to see how different training rates impacted the effectiveness of the gradient descent.
- I then applied the transformation matrix to all Swedish word vectors to obtain corresponding vectors that are then comparable to the English word vectors.
Inspecting some example words and their translations indicates that the translation works quite well, as illustrated by the shift in Swedish word vectors between Figure 1 and Figure 2:
Figure 1: Scatterplot showing a selection of English words (red) and their corresponding Swedish words (blue), connected by light grey lines, when the word vectors are projected onto the first two principal components derived from running PCA on the English word vectors:
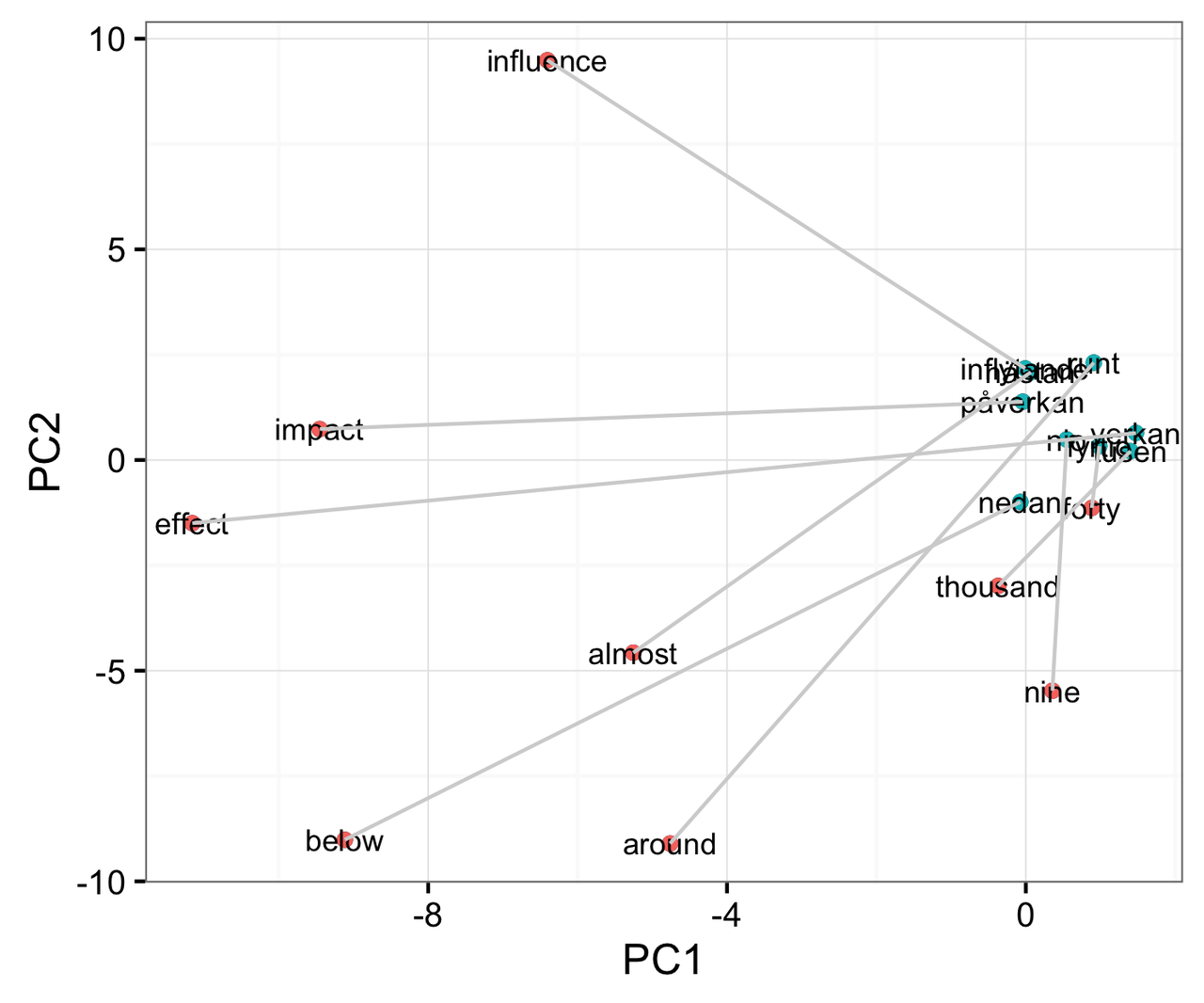 Technical note: Swedish word vectors can be projected onto the English principal components 1 and 2, as the Swedish and English word vectors just happen to be the same length (400 elements). This is done in figure 1 simply to contrast against their updated positions as shown in figure 2, after the translation matrix is applied.
Technical note: Swedish word vectors can be projected onto the English principal components 1 and 2, as the Swedish and English word vectors just happen to be the same length (400 elements). This is done in figure 1 simply to contrast against their updated positions as shown in figure 2, after the translation matrix is applied.
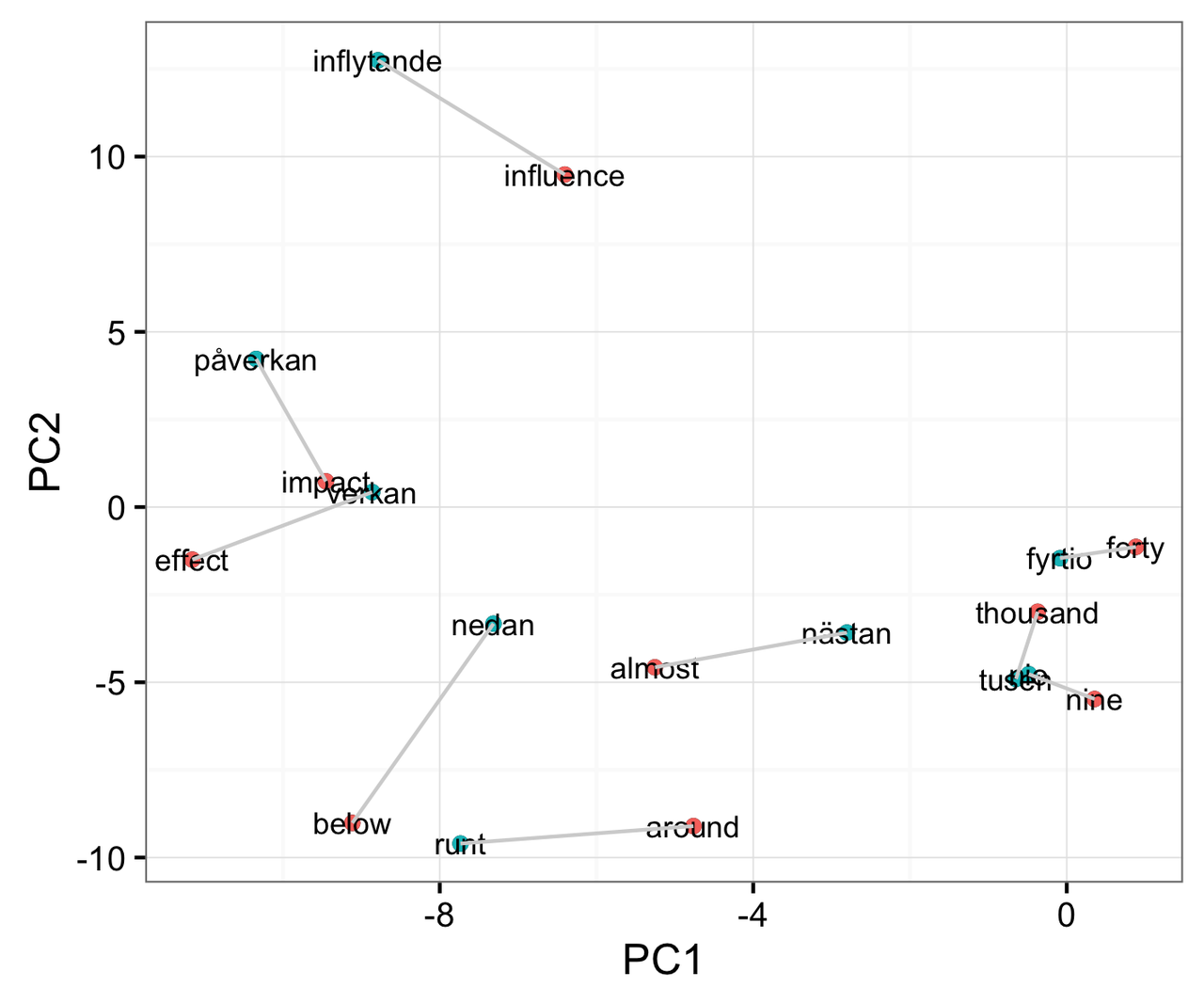
Figure 2: When I multiply the Swedish word vectors with the translation matrix, the word vectors move much close to their respective English counterparts:
Mitigating the "curse of dimensionality"
Given word vectors for English and Swedish (translated to English word vector coordinates), I now set out to compare the languages based on the positioning of the word vectors in high dimensional space. This was by far and away the trickiest and most time-consuming aspect of the project, and I ended up trying a few different approaches to the problem.
To get optimal performance, word vectors are high dimensional (typically hundreds of dimensions). The high dimensionality of the resulting data can cause various problems. In this project, data sparsity was a particular problem: I needed to find a way to compare the English and Swedish word vector landscapes in spite of the great sparsity of the word vector instances. Given 400 dimensions, a volume in that space will typically contain few word vectors.
I tried applying PCA and doing a comparison of word density in volumes defined by the resulting lower number of dimensions, and I tried out the t-SNE method too.
My goal was to identify areas of linguistic expression enriched in one language relative to another, and so I eventually decided I should define clusters of words within similar meaning, and then analyse those on aggregate. To do this, I used gensim to find the closest 100 English word vectors for each English word, as defined by cosine similarity. I then defined a graph) of word similarity, with words as nodes and edges between nodes if the two words have cosine similarity > 0.5. Taking this graph as input, I ran the InfoMap tool to detect clusters of highly interconnected words. For each of the word clusters, I also calculated the median cosine similarity value to the closest Swedish word, considering all words in the cluster.
Using this approach produced more robust results compared with an approach analysing individual words in isolation.
Highly translatable words
I consider the median Swedish cosine similarity to be a proxy for the translatability of a given word cluster - i.e. word clusters with a high score contain words that typically have a good translation, whilst word clusters with a low score contain words with mostly poor translations.
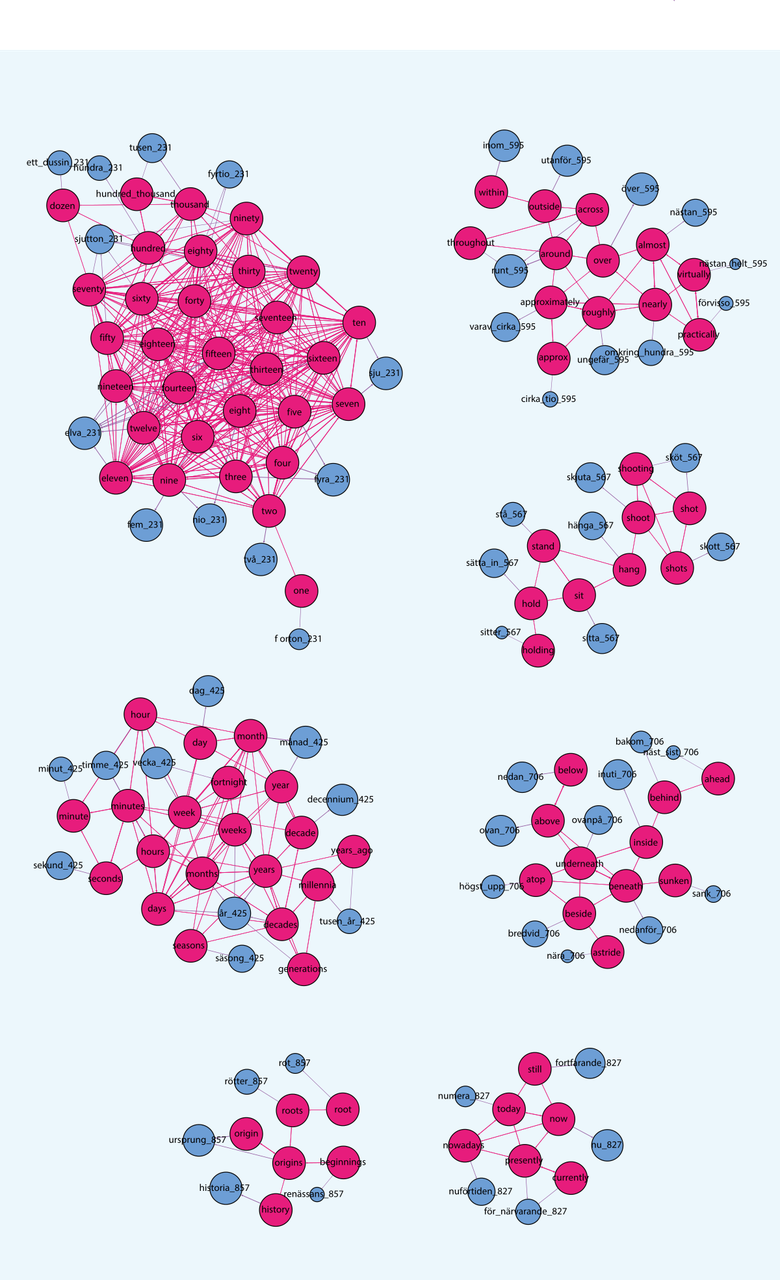
Looking at the clusters with highest translatability, we can see that the clusters deal with universal concepts that are not tethered to culture, including numbers, physical positioning, time, or physical actions, as shown in Figure 3.
Figure 3: Clusters of similar English words (red nodes) with high median cosine similarity of their closest Swedish translations (blue nodes), defined through use of InfoMap. Visualisation generated with Gephi. Edges between English word nodes indicate cosine similarity > 0.5, whereas an edge to a Swedish word node indicates the translation with highest cosine similarity for the given English word. The size of Swedish word nodes is scaled to the maximum observed cosine similarity score for that word. Note: The numeric values associated with the Swedish words are a technical artefact, and can be ignored.
Cultural insights: The Jantelagen and the Swagman
Some of the clusters with low translatability scores reveal potentially cultural differences between Swedish- and English-speaking populations. I considered the clusters in the lowest 10% of translatability (72 clusters in total), and present illustrative examples here (more extensive results are presented in the appendix).
One unspoken rule underpinning Scandinavian societies is the "Jantelagen". Under the Jantelagen, it is taboo to promote oneself as having greater merit or achievement compared to others. As such, it is perhaps no surprise that English words such as eclipsed, surpassed, rivaled, bettered and outpaced are difficult to translate to Swedish equivalents (Figure 4).
Figure 4: English words that appear to violate the Swedish Jantelagen (see Figure 3 caption for legend).

Scandinavian societies are also famous for being highly egalitarian - a concept extending beyond the Jantelagen itself. My method identifies several relevant clusters of English words that are indeed not very egalitarian in tone. In Figure 5 we can see a cluster of words containing various occupations. Some of these arguably exist solely for rich people to flaunt their wealth - such as butlers or valets, and others might be considered old fashioned, such as housekeepers or homemakers. In a similar vein, words like profiteering, mongering, debased, and bullish seem to run counter to ideals of equality.
Figure 5: English words and concepts that run counter to egalitarianism.
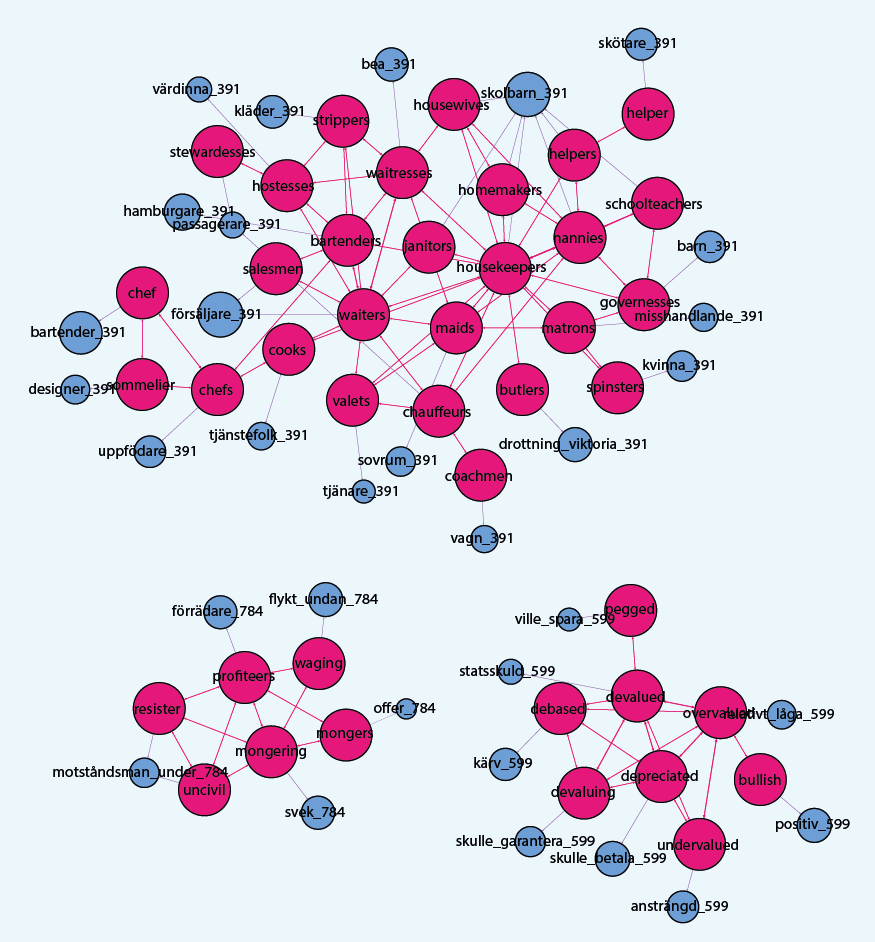
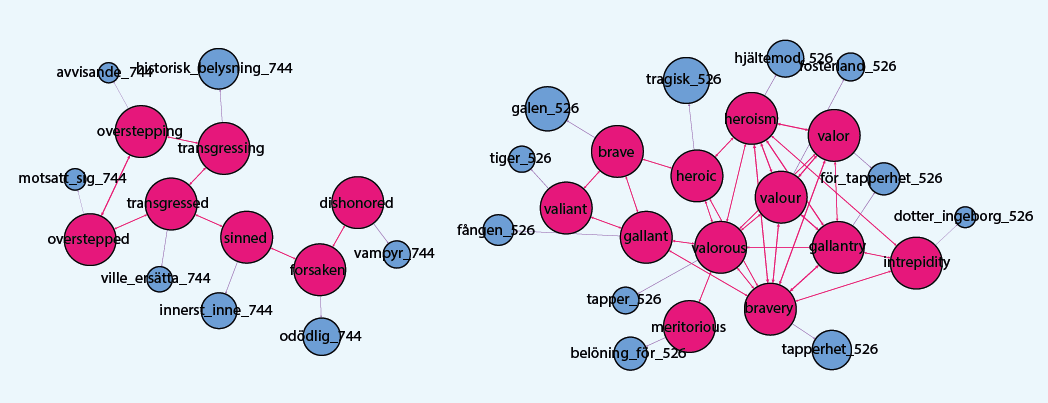
Figure 6 shows a cluster of morality-related verbs such as sinned and transgressed, and a cluster of nouns/adjectives relating to virtues, including valour and gallantry. These are concepts that vary from culture to culture; such ideas could be considered pompous or pious depending on your point of view.
Figure 6: English words relating to virtue concepts that translate poorly to Swedish.
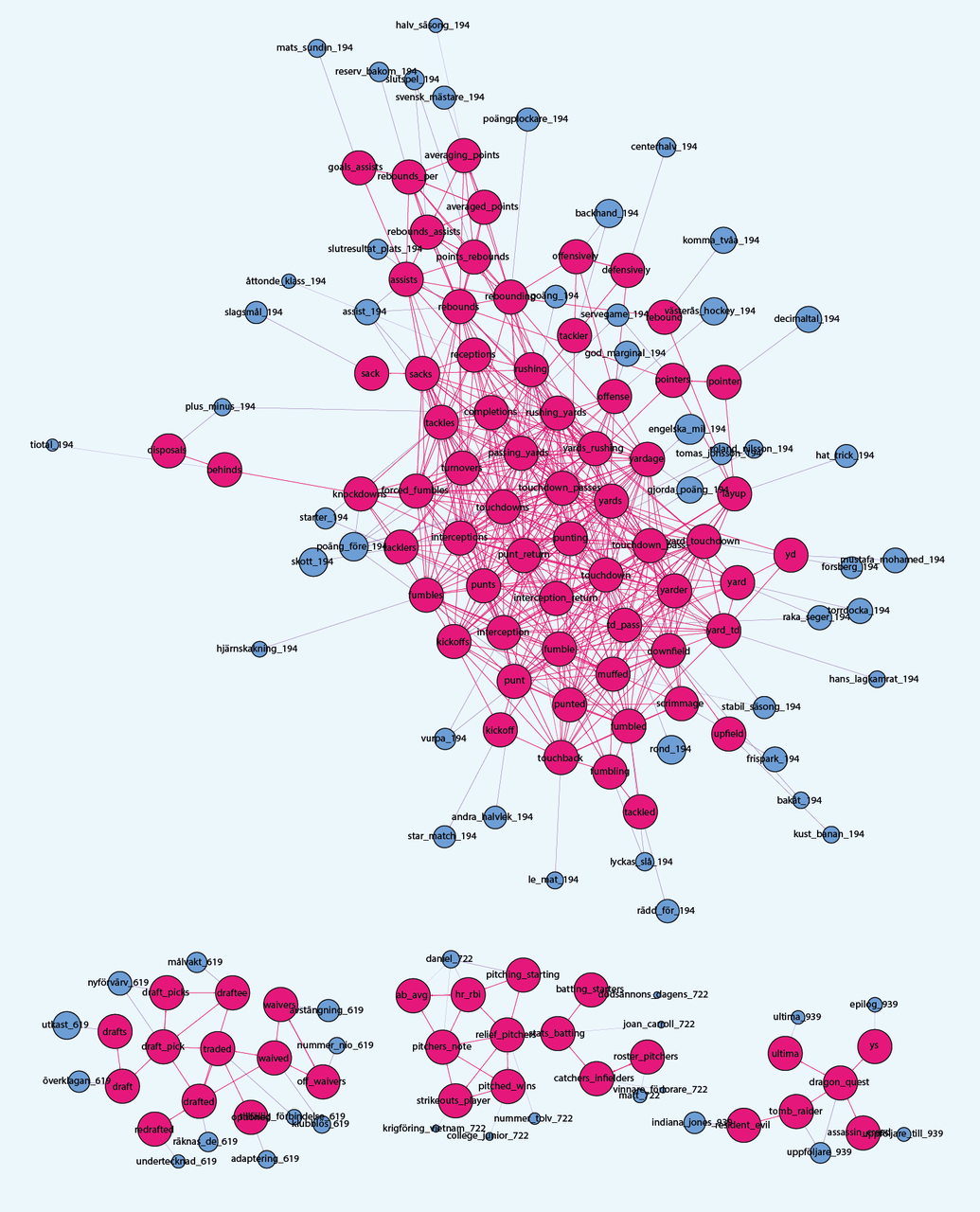
Various English word clusters relating to north american sporting terminology (baseball, gridiron football) as well as famous computer games (ultima, resident evil) also translate poorly into Swedish (Figure 7). This is clearly an expected result, as Swedes simply revert to using the English terminology when discussing such topics.
Figure 7: Sporting/gaming terms that translate poorly to Swedish.
Finally, as an Australian, here is my favourite result of all:
Figure 8: Archaic professions of the Australian bush
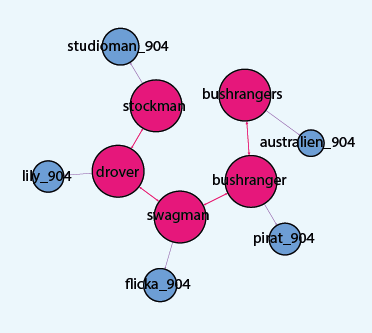
Of course, most Swedes will have not the foggiest of what a bushranger or a swagman is. These words are all professions in the Australian outback, in colonial times. A swagman was someone a bit down on their luck, travelling around the Australian bush looking for work here and there (Figure 9).
Figure 9: A swagman

The method gets fairly close for "bushranger", coming up with the Swedish word "pirat" (which is equivelant to the English word "pirate"). Bushrangers were people hiding in the bush to evade the authorities, occasionally fighting the police (Figure 10).
Figure 10: No, Swedes, that's not a Södermalm hipster. It's Ned Kelly, Australia's most famous bushranger, with his home-made suit of armour!

Perspectives
If someone asked me,
"What did you find, in your quest for the word vectors?"
I would answer:

The project was a lot of fun and I have learnt some new skills whilst doing it, including how to analyse and visualise word vectors, and implementing the gradient descent using Theano.
I am reasonably confident in the veracity of my findings, with some caveats (see appendix). On the whole, this approach seems to turn up some genuine areas of linguistic expression that are enriched in one language relative to another (in this case English vs Swedish). By inspecting the sets of words enriched in English relative to Swedish, the method seems to produce insights into cultural differences between the English- and Swedish-speaking communities.
Rigorous quantification of something as hard-to-define as human culture has important and beneficial applications.
As for future follow on work. Word vectors are, indeed, very cool. But thought vectors - are even cooler! The ability to quantify individual thoughts could be a boon to humanity when coupled with good visualisation techniques. They could (for example) be used to augment human's understanding of various topics, granting permanence and elucidating what is otherwise ephemeral and complex.
Thank you for reading!
UPDATE (2023-02-03): This whole blog post is in many ways hopelessly outdated. But in particular I want to make a remark regarding the above "thought vectors": Arguably better terms for this could be "sentence embeddings", "contextualized word embeddings" - the kind of thing you get out of BERT and similar large language models.
Acknowledgements
I wish to thank Mattias Östmar and Mikael Huss, who provided great insights and feedback throughout the project.
Appendix
This analysis has all been carried out in my spare time, so I have not approached it from as many angles I perhaps otherwise would do. I believe it is quite rigorous on the whole, but there are some a few caveats that I feel are important to point out.
The first is a general point: this method ultimately reflects differences between the corpora underlying the two sets of word vectors compared. Thus it will only reflect true differences in culture when the corpora are comparable - if I took English wikipedia and compared it against Swedish twitter data, I imagine the results would primarily reflect differences between wikipedia and twitter, rather than Swedish and English. I found it was important to filter word vectors to exclude those that are not true Swedish or English words - otherwise the final results were polluted by gibberish.
Another caveat is the reliance of the final step on what is ultimately a manual interpretation of the results; I looked at the English-enriched word clusters and offered my interpretation based on what I know about the languages and cultures. There are clearly different ways to interpret the same results. Replication of this technique on other corpus and language pairings could determine how robust these findings are.
There are also some obvious artefacts in the final results. For example, several Swedish-depleted English word clusters were actually not English words, but were words from another language (Figure 11).
Figure 11: Artefact word clusters - foreign language clusters

Finally, the least-translatable 72 (10% of all) English word clusters also included some results that seem to reflect culture in some way, which didn't fit into the main results section above. Here they are:
Figure 12: Additional results of interest

Social media:
If you would like to get in touch, here's my social media:
- LinkedIn: https://www.linkedin.com/in/tomwhitington
- Twitter: @Tom_Whitington
- Mastodon: @tomwhitington@sigmoid.social
Comments
Comments powered by Disqus